

The Importance of Data Analysis in Machine Learning
In the current era of digital transformation, data analysis serves as the backbone of machine learning (ML), empowering organizations to make informed decisions based on empirical evidence. The staggering amounts of data generated daily—from social media interactions to transactional records—present both challenges and opportunities. The ability to effectively harness and analyze this data is essential for enhancing the predictive capabilities of various machine learning models.
The journey of effective data analysis in machine learning begins with data collection. This step requires the aggregation of diverse datasets from multiple sources, including internal databases, public datasets, and real-time feeds. For instance, a retail company may pull data from its sales transactions, customer feedback, and online browsing patterns to create a holistic view of consumer behavior. This comprehensive data gathering lays the foundation for deeper insights.
Once the data is collected, the next critical phase is data cleaning. This step involves the meticulous process of identifying and rectifying inaccuracies, inconsistencies, and outliers within the data. Failing to conduct proper data cleaning can lead to the development of biased or ineffective ML models. For example, in a financial application, incorrect transaction data can skew credit scoring algorithms, leading to poor lending decisions. Hence, ensuring high-quality inputs is paramount in setting the stage for reliable machine learning outputs.
The process does not stop there; feature selection is equally vital. This involves sifting through the collected data to determine which variables significantly influence the model’s predictions. Utilizing techniques such as correlation coefficients and decision trees, practitioners can identify key features that drive results. For example, in predicting house prices, attributes such as location, square footage, and the number of bedrooms are often more relevant than less impactful features like paint color. Selecting the right variables can substantially improve model accuracy and efficiency.
As organizations across many sectors harness these analytical processes, the transformative potential of data analysis becomes evident. In healthcare, for instance, precise data analysis aids in predictive analytics, allowing medical practitioners to anticipate patient needs and streamline treatment. Similarly, in the financial sector, firms employ data analysis for risk assessment and fraud detection, leading to insights that not only improve security but also foster greater customer trust in the services provided.
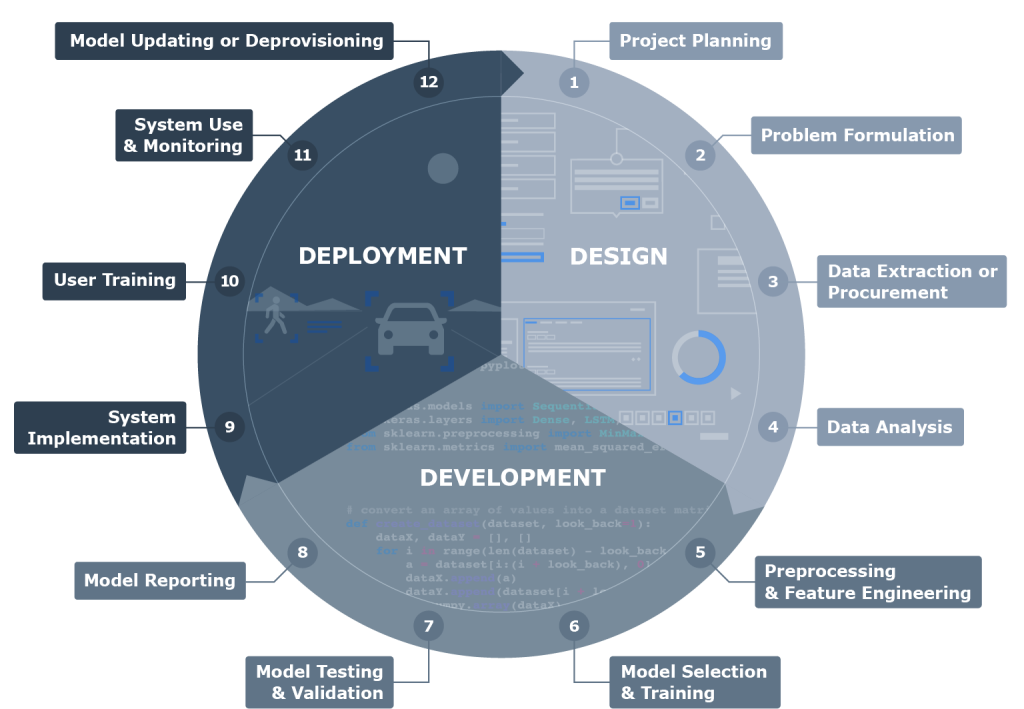
As one explores the intricate relationship between data analysis and machine learning, the importance of mastering these skills emerges as a critical factor for success in the field of artificial intelligence. The synergy between data preparation and machine learning can unlock new dimensions of innovation, driving advancements that ripple through industries and influence everyday life.
Ultimately, understanding and refining data analysis techniques is not just a technical necessity; it is a foundational element that can propel organizations towards a future where data-driven insights lead to strategic advantages and transformative solutions.
DISCOVER MORE: Click here to learn how AI is transforming patient care
Understanding the Data Science Pipeline
The foundational role of data analysis in training machine learning models extends through the various stages of the data science pipeline. Each phase is interconnected, emphasizing the necessity of a structured methodology that ultimately impacts the performance and reliability of machine learning algorithms. This dedicated approach allows organizations to derive meaningful insights from their data, fostering improved decision-making processes that are essential in today’s data-driven environment.
The Importance of Data Preparation
Data preparation is a crucial step that cannot be overlooked. It encompasses both data cleaning and data transformation. During this phase, analysts refine the data by removing duplicate entries, handling missing values, and standardizing formats. This meticulous attention to data quality is essential for training robust machine learning models; inadequate or erroneous data can lead to misleading outcomes and negatively affect model performance.
Acknowledging the impact of data preparation, companies are increasingly investing in tools and technologies designed to streamline this process. Advanced data wrangling techniques, from automated cleaning tools to sophisticated ETL (Extract, Transform, Load) systems, play a pivotal role in facilitating efficient data preprocessing. If organizations overlook this stage, the likelihood of developing models that can make inaccurate predictions escalates dramatically.
Exploring Data Visualization
Another critical aspect of data analysis in the machine learning pipeline is data visualization. Visual representation of data not only enhances the understanding of complex datasets but also facilitates the identification of patterns and trends that might otherwise remain hidden. By employing various visualization techniques, such as scatter plots, heat maps, and histograms, data analysts can provide actionable insights that inform model selection and feature engineering.
For example, consider a retail scenario where a company wants to analyze customer buying patterns. By visualizing purchase data, analysts might discover that certain products are often bought together, leading to opportunities for effective cross-selling strategies. Furthermore, visual analytics can help to assess the impact of outliers on model training, revealing whether specific data points should be included or excluded to enhance accuracy.
Feature Engineering: Crafting the Right Input
Beyond data cleaning and visualization, feature engineering plays a central role in optimizing machine learning performance. This involves creating new variables or modifying existing ones to improve model predictions. Since many algorithms depend on the features selected to learn from the data, investing time and expertise into this stage can yield significant dividends.
- Domain Knowledge: By leveraging insights from relevant domains, data scientists can generate features that are directly tied to business objectives.
- Feature Interactions: Identifying interactions between features and combining them can reveal critical relationships, increasing model sensitivity to changes in data.
- Temporal Features: Incorporating time-based features can enhance the predictability of behaviors that change over time, such as consumer purchasing trends.
In summary, the stages of data preparation, visualization, and feature engineering form the bedrock of the data analysis process for machine learning. As organizations continue to cultivate their data-focused strategies, understanding these components becomes increasingly vital. The effectiveness of the machine learning models they develop depends heavily on the quality and depth of data analysis employed throughout their training, ultimately helping companies harness the full potential of their data assets.
The Importance of Data Quality in Machine Learning
Data quality is paramount when it comes to training machine learning models. High-quality data ensures that models are accurate and robust, enabling them to generalize well on unseen data. Poor data quality can lead to biased models, which can significantly impact decision-making processes. Therefore, data analysis plays a critical role in identifying inconsistencies, gaps, and noise within datasets. Moreover, understanding the nature of the data is vital. For instance, categorical variables must be correctly encoded, and continuous variables often require normalization or scaling. Through extensive data analysis, practitioners can uncover patterns and relationships within the data, providing valuable insights that guide model selection and feature engineering.In addition, data analysis helps in performing exploratory data analysis (EDA), where trends, distributions, and correlations are discovered. EDA can reveal hidden structures in the data that can be exploited to improve model performance. It equips machine learning practitioners with the necessary tools to preprocess and prepare data effectively, enhancing the training process.
Feature Selection: A Key Component
Feature selection is another crucial aspect facilitated by data analysis. It involves selecting a subset of relevant features for use in model construction. By eliminating irrelevant or redundant variables, practitioners can improve model interpretability and reduce overfitting. Data analysis aids in identifying which features contribute most to the predictive power of models, streamlining the training process.Various methods, including statistical tests and algorithms like Recursive Feature Elimination (RFE), provide insights into the importance of different features. Leveraging such analytical tools can significantly enhance a model’s predictive accuracy.As machine learning continues to evolve, the integration of advanced data analysis techniques not only optimizes the training of machine learning models but also opens up avenues for more informed, data-driven decision-making across various industries.
| Category | Advantages |
|---|---|
| Enhanced Model Accuracy | Utilizing data analysis reveals patterns, leading to better predictions. |
| Informed Decision Making | Data-driven insights improve strategic planning and operational efficiency. |
The integration of data analysis at every stage of machine learning training cannot be overstated. Each analysis step leads to a more informed and effective modeling process, ultimately contributing to superior outcomes and greater operational efficiencies.
DISCOVER MORE: Click here to learn about the ethics of machine learning
Model Evaluation: Ensuring Predictive Reliability
After significant effort has been dedicated to the preparation and engineering of data, the next essential phase in the machine learning pipeline is model evaluation. This process involves assessing the performance of trained models to ensure they can generalize well to new, unseen data. Strong data analysis methodologies lend themselves to identifying relevant metrics and validating the model’s predictive capabilities.
Choosing the Right Metrics
When it comes to model evaluation, selecting appropriate metrics is crucial. Different problems require different approaches. For instance, if a model is developed for a classification task, metrics such as accuracy, precision, and recall become vital indicators of performance. In contrast, regression tasks typically rely on metrics like mean absolute error and R-squared. Understanding the nuances of these metrics allows data analysts to interpret results accurately and make informed decisions about model adjustments.
Furthermore, confusion matrices, ROC curves, and AUC (Area Under the Curve) scores are additional tools that can provide deeper insights into model performance, helping to visualize where models may exceed or lag behind. Using these analytical techniques responsibly can empower organizations to maintain a competitive edge by minimizing the risks of deploying faulty models.
Cross-Validation: Robustness in Model Assessment
Cross-validation is another data analysis technique that has gained traction for its ability to provide more reliable performance estimates. By partitioning the dataset into multiple subsets, analysts can train the model on a portion of the data while validating it on another. This iterative process not only ensures that models do not simply memorize the training data but also highlights the model’s ability to generalize to new data. Techniques such as K-fold cross-validation enhance the robustness of model evaluation, contributing to the selection of the optimal model for deployment.
Hyperparameter Tuning: Fine-tuning for Optimal Performance
Once the model is evaluated, the next step often involves hyperparameter tuning. Hyperparameters are the configurations that govern the training process of machine learning algorithms. These parameters, which are set prior to training, can significantly influence model performance. Data analysts utilize techniques such as grid search and random search to systematically explore different combinations of hyperparameters. This meticulous process aims to identify a set of parameters that yields the best results based on validation performance.
- Grid Search: This approach involves exhaustively searching through predetermined combinations of hyperparameters to identify the optimal configuration.
- Random Search: By randomly sampling from the hyperparameter space, this method can sometimes identify favorable models more efficiently than grid search.
Data analysis thus plays a pivotal role in ensuring that hyperparameter tuning is systematic and comprehensive, guiding analysts in the quest for improved model performance.
Deployment and Continuous Monitoring
Finally, data analysis does not end with model training and evaluation. Upon deployment, continuous monitoring becomes essential to verify whether models perform as expected in real-world scenarios. Utilizing analytics tools and dashboards can provide real-time insights into model performance, allowing data scientists to detect issues before they manifest into significant problems.
By establishing metrics and a feedback loop post-deployment, organizations can continually enhance their models, ensuring they adapt to any changes in the underlying data patterns or operational circumstances. This ongoing vigilance is a fundamental aspect of leveraging data analysis for machine learning success.
DIVE DEEPER: Click here to uncover more insights
Conclusion: The Indispensable Role of Data Analysis in Machine Learning
The journey of training machine learning models is entwined with the intricate processes of data analysis. As we navigate through stages such as model evaluation, metric selection, and hyperparameter tuning, the importance of a robust data analysis strategy becomes increasingly clear. Accurate data analysis empowers organizations to make informed choices, transforming raw data into actionable insights that drive machine learning success.
In today’s data-driven landscape, every decision hinges on the accuracy and reliability of analytical methods. The metrics chosen can dictate the trajectory of model effectiveness, influencing its ability to make real-world predictions. Incorporating advanced techniques like cross-validation enhances the model’s resilience, assuring stakeholders that their investments yield valuable returns. As hyperparameter tuning fine-tunes models to their optimal configurations, it becomes evident that data analysis does not merely contribute to the pre-deployment phase but ensures prolonged performance post-deployment.
Moreover, the need for continuous monitoring underscores a philosophy of dynamic adaptation. By leveraging real-time analytics, organizations not only safeguard their models against obsolescence but also maintain their competitive edge. As industries evolve and data landscapes shift, the capability to continually recalibrate models through vigilant data analysis becomes critical to harnessing the full potential of machine learning.
For those poised to delve deeper into the realm of machine learning, embracing the art of data analysis is not just beneficial; it is essential. As technology progresses, exploring the intersection of data analysis and machine learning will undoubtedly yield profound insights and open new avenues for innovation. The future is bright for those who recognize that successful machine learning begins with the mastery of data.

